
What is Sharding for Blockchains?
Sharding is a technique used to enhance the scalability of blockchain networks in multiple ways.
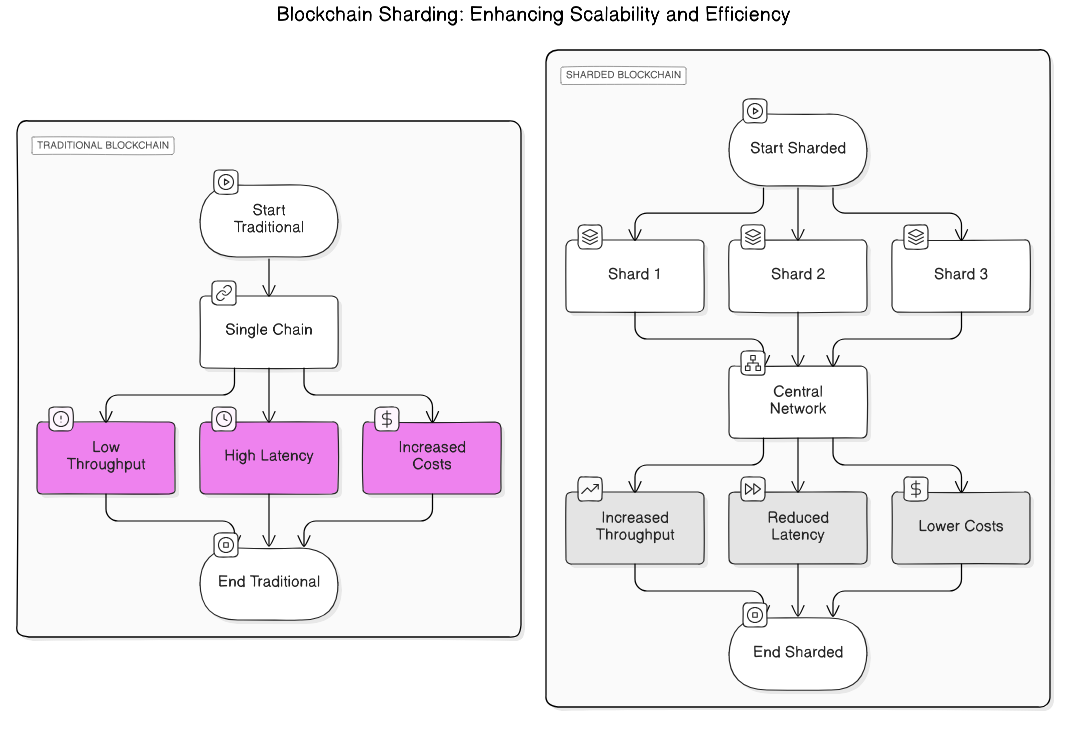
To understand sharding properly, let’s start with its fundamental principle. The basic premise of sharding involves dividing information into multiple shards, which can potentially increase storage capacity. Think of it like organizing a massive library by splitting books across different sections – this approach can be used to enhance overall performance in a systematic way.
When we apply this concept to cryptocurrency processing, sharding involves splitting the blockchain network into smaller, more manageable segments. Each segment, called a shard, holds a unique set of smart contracts and account balances. This design allows nodes to be assigned to individual shards to verify transactions and operations, rather than requiring each node to be responsible for every single transaction across the entire network. Through this division of labor, sharding can significantly improve transaction throughput and address the scalability bottlenecks that many existing blockchains face today.
However, it’s important to understand that sharding introduces new challenges, particularly in terms of security. Ensuring that each shard remains secure while maintaining the tamper-proof nature of transaction validation and recording becomes critically important. Another significant challenge lies in the increased complexity for developers, who must implement specialized communication mechanisms to enable users and applications to interact seamlessly across different shards. To address these concerns, techniques such as cross-shard communication and specific consensus mechanisms are employed to maintain the overall security of the system.
Sharding for Data Availability
The evolution of Ethereum’s approach to sharding provides an excellent case study for understanding how blockchain development adapts to real-world challenges. Initially, the Ethereum blockchain planned to introduce a comprehensive level of sharding that would split the entire network into different shards. However, this ambitious idea has largely been placed on the back-burner as the development community recognized more practical solutions.
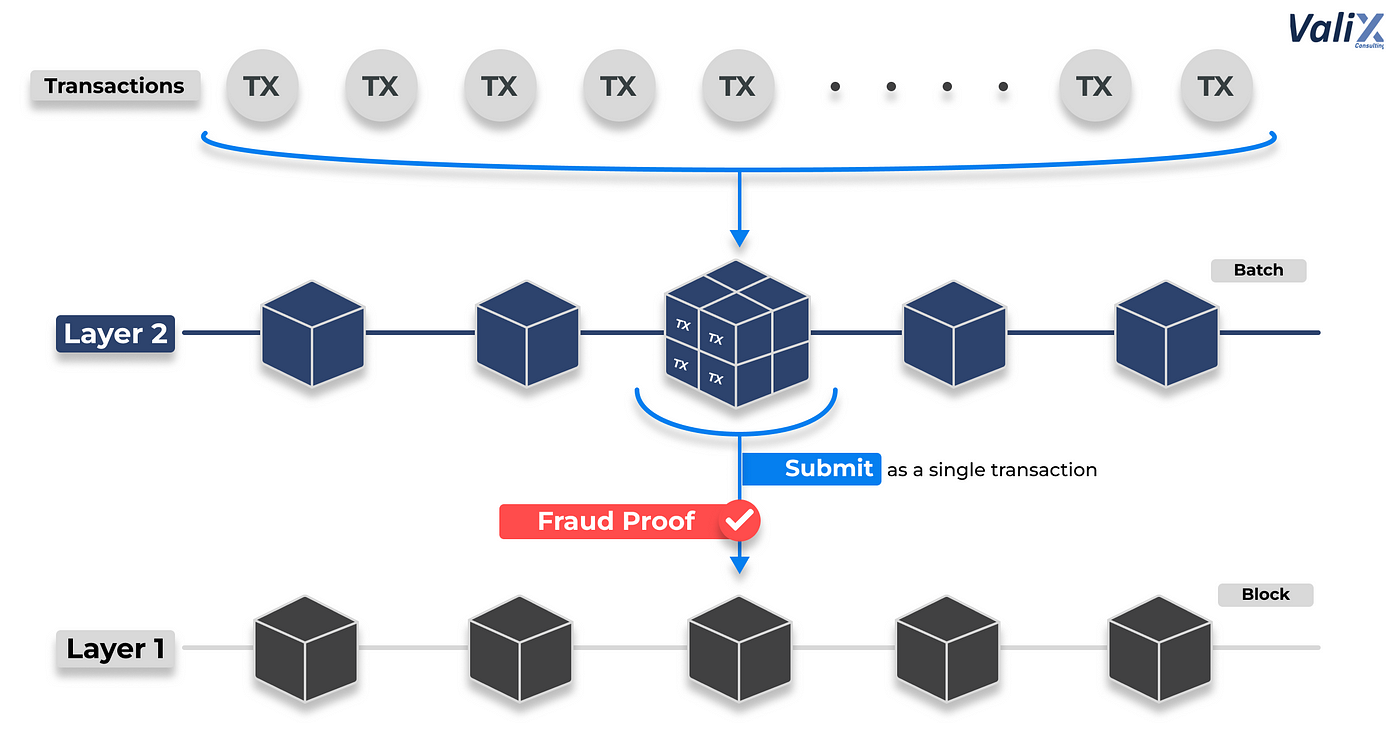
Instead of pursuing deep network sharding, there has been an increased focus on scaling the network through multiple layers, known as Layer 2 networks, which utilize rollup technology. These layers process large volumes of transactions that are effectively batched and then submitted to the base layer. This approach represents a more incremental and manageable path toward scalability.
Nevertheless, Layer 2 networks present their own set of challenges that we must consider. Beyond the ongoing concerns about decentralization, these solutions also create issues related to data availability, particularly because they handle such enormous numbers of transactions that need to be verified and stored.
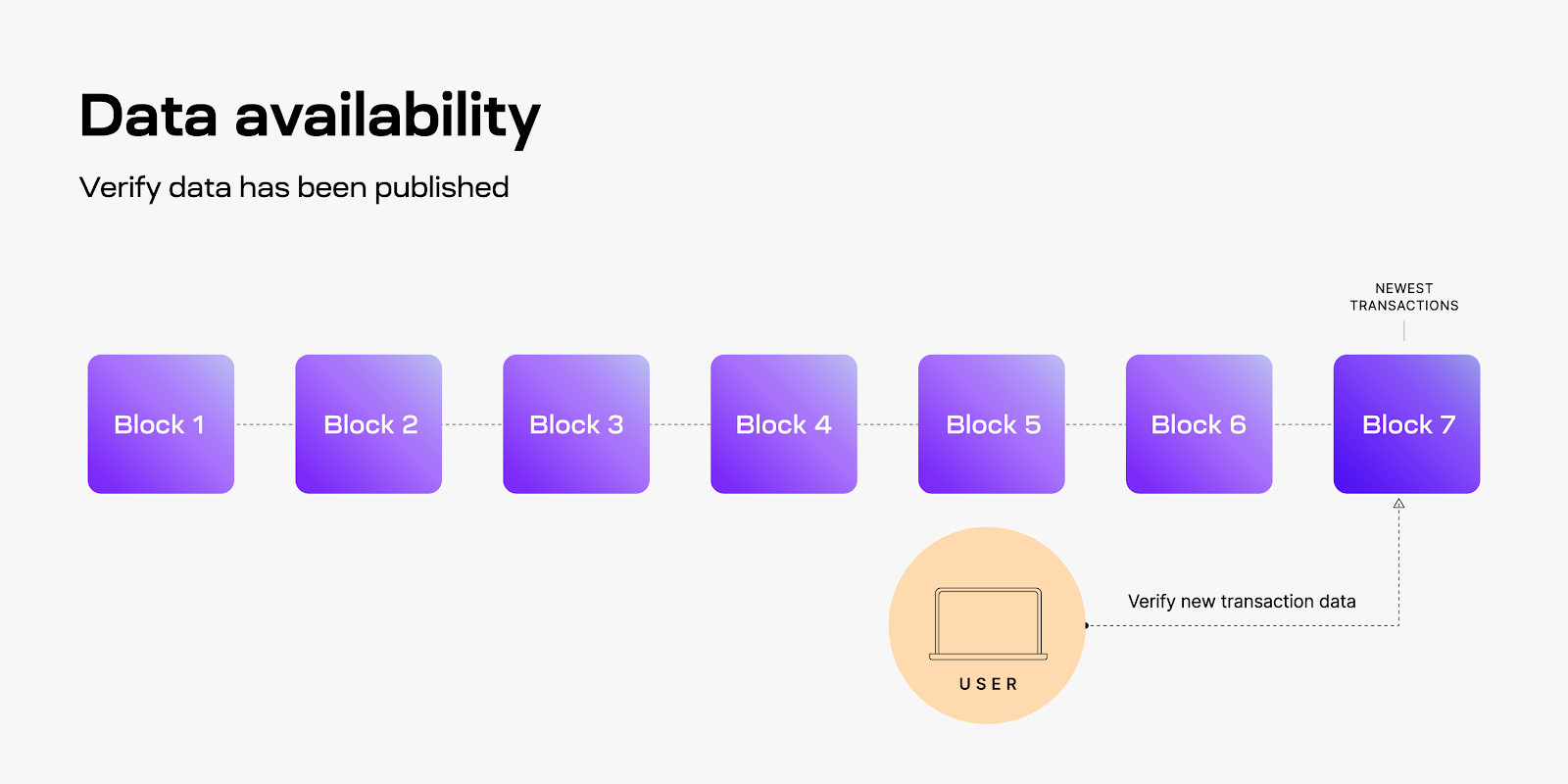
This is where Ethereum’s current focus on sharding becomes particularly interesting. Rather than using sharding to split the entire network, Ethereum is now concentrating on using sharding specifically to solve data availability problems, with the goal of helping the network better support its scaling layers. The key challenge here involves enabling rollups to batch such large amounts of data to the base layer in a way that validators can efficiently confirm the data’s availability.
Ethereum co-founder Vitalik Buterin has proposed an innovative solution to this problem. His idea centers on having the Ethereum blockchain include shards that would specifically affirm the availability of data deposited from Layer 2 networks. The proposed mechanism would combine a randomly selected committee with random sampling techniques to verify the availability of such data, creating a robust system for ensuring data integrity while maintaining efficiency.


